Ending an Ugly Chapter in Chip Design
Discussions at chip design conferences rarely get heated. But a year ago at the International Symposium on Physical Design, things got out of hand. It was described by observers as a “trainwreck” and an “ambush”. The crux of the clash was whether Google’s AI solution to one of chip design’s thornier problems was really better than humans or state-of-the-art algorithms. It pitted established male EDA experts against two young female Google computer scientists, and the underlying argument had already led to the firing of one Google researcher.
This year at that same conference, a leader in the field, IEEE Fellow Andrew Kahng, hoped to put an end to the acrimony once and for all. He and colleagues at University of California, San Diego delivered what he called an “an open and transparent assessment” of Google’s reinforcement learning approach. Using Google’s open-source version of its process, called Circuit Training, and reverse-engineering some parts that were not clear enough for Kahng’s team, they set reinforcement learning against a human designer, commercial software, and state-of-the-art academic algorithms. Kahng declined to speak with IEEE Spectrum for this article, but he spoke to engineers last week at ISPD, which was held virtually.
In most cases, Circuit Training was not the winner, but it was competitive. That’s especially notable given that the experiments did not allow Circuit Training to use its signature ability—to improve its performance by learning from other chip designs.
“Our goal has been clarity of understanding that will allow the community to move on,” he told engineers. Only time will tell whether it worked.
The Hows and the Whens
The problem in question is called placement. Basically, it is the process of determining where chunks of logic or memory should be placed on a chip in order to maximize the chip’s operating frequency while minimizing its power consumption and the area it takes up. Finding an optimal solution to this puzzle is among the most difficult problems around, with more possible permutations than the game Go.
But Go was ultimately defeated by a type of AI called deep reinforcement learning, and that’s just what former Google Brain researchers Azailia Mirhoseini and Anna Goldie applied to the placement problem. The scheme, then called Morpheus, treats placing large pieces of circuitry, called macros, as a game, learning to find an optimal solution. (The locations of macros have an outsized impact on the chip’s characteristics. In Circuit Training and Morpheus, a separate algorithm fills in the gaps with the smaller parts, called standard cells. Other methods use the same process for both macros and standard cells.)
Briefly, this is how it works: The chip’s design file starts as what’s called a netlist—which macros and cells are connected to which others according what constraints. The standard cells are then collected into clusters to help speed up the training process. Circuit Training then starts placing the macros on the chip “canvas” one at a time. When the last one is down, a separate algorithm fills in the gaps with the standard cells, and the system spits out a quick evaluation of the attempt, encompassing the length of the wiring (longer is worse), how densely packed it is (more dense is worse), and how congested the wiring is (you guessed it, worse). Called proxy cost, this acts like the score would in a reinforcement learning system that was figuring out how to play a video game. The score is used as feedback to adjust the neural network, and it tries again. Wash, rinse, repeat. When the system has finally learned its task, commercial software does a full evaluation of the complete placement, generating the kind of metrics that chip designers care about, such as area, power consumption, and constraints on frequency.
Mirhoseini and Goldie published the results and method of Morpheus in Nature in June 2021, following a seven-month review process. (Kahng was reviewer #3.) And the technique was used to design more than one generation of Google’s TPU AI accelerator chips. (So yes, data you used today may have been processed by an AI running on a chip partly designed by an AI. But that’s increasingly the case as EDA vendors such as Cadence and Synopsys go all in on AI-assisted chip design.) In January 2022, they released an open-source version, Circuit Training, on GitHub. But Kahng and others claim that even this version was not complete enough to reproduce the research.
In response to the Nature publication, a separate group of engineers, mostly within Google, began research aimed at what they believed to be a better way of comparing reinforcement learning to established algorithms. But this was no friendly rivalry. According to press reports, its leader Satarjit Chatterjee, repeatedly undermined Mirhoseini and Goldie personally and was fired for it in 2022.
While still at Google, Chatterjee’s team produced a paper titled “Stronger Baselines”, critical of the research published in Nature. He sought to have it presented at a conference, but after review by an independent resolution committee, Google refused. After his termination, an early version of the paper was leaked via an anonymous twitter account just ahead of ISPD in 2022, leading to the public confrontation.
Benchmarks, Baselines, and Reproducibility
When IEEE Spectrum spoke with EDA experts following ISPD 2022, detractors had three interrelated concerns—benchmarks, baselines, and reproducibility.
Benchmarks are openly available blocks of circuitry that researchers test their new algorithms on. The benchmarks when Google began its work were already about two decades old, and their relevance to modern chips is debated. University of Calgary professor Laleh Behjat compares it to planning a modern city versus planning a 17th century one. The infrastructure needed for each is different, she says. However, others point out that there is no way for the research community to progress without everyone testing on the same set of benchmarks.
Instead of the benchmarks available at the time, the Nature paper focused on doing the placement for Google’s TPU, a complex and cutting-edge chip whose design is not available to researchers outside of Google. The leaked “Stronger Baselines” work placed TPU blocks but also used the old benchmarks. While Kahng’s new work also did placements for the old benchmarks, the main focus centered on three more modern designs, two of which are newly available, including a multicore RISC-V processor.
Baselines are the state-of-the art algorithms your new system competes against. Nature compared a human expert using a commercial tool to reinforcement learning and to the leading academic algorithm of the time, RePlAce. Stronger Baselines contended that the Nature work didn’t properly execute RePlAce and that another algorithm, simulated annealing, needed to be compared as well. (To be fair, simulated annealing results appeared in the addendum to the Nature paper.)
But it’s the reproducibility bit that Kahng was really focused on. He claims that Circuit Training, as it was posted to GitHub, fell short of allowing an independent group to fully reproduce the procedure. So they took it upon themselves to reverse engineer what they saw as missing elements and parameters.
Importantly, Kahng’s group publicly documented the progress, code, datasets, and procedure as an example of how such work can enhance reproducibility. In a first, they even managed to persuade EDA software companies Cadence and Synopsys to allow the publication of the high-level scripts used in the experiments. “This was an absolute watershed moment for our field,” said Kahng.
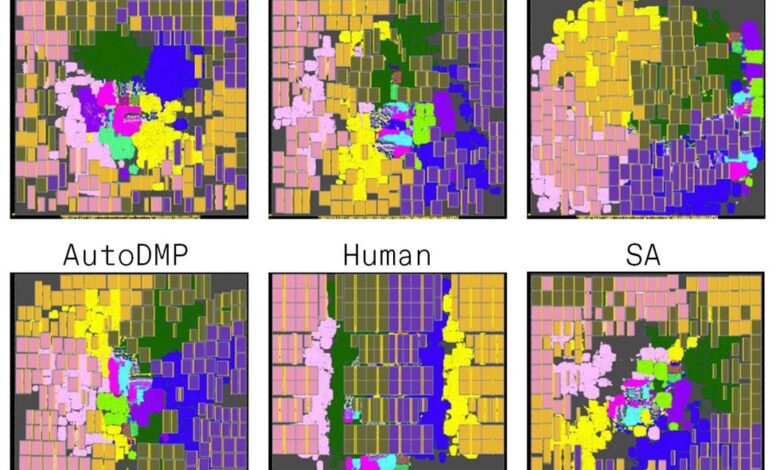
The UCSD effort, which is referred to simply as MacroPlacement, was not meant to be a one-to-one redo of either the Nature paper or the leaked Stronger Baselines work. Besides using modern public benchmarks unavailable in 2020 and 2021, Macro Placement compares Circuit Training (though not the most recent version) to a new commercial tool, Cadence’s Innovus concurrent macro placer (CMP), and to a method developed at Nvidia called AutoDMP that is so new it was only publicly introduced at ISPD 2023 minutes before Kahng spoke.
Reinforcement Learning vs. Everybody
Kahng’s paper reports results on the three modern benchmark designs implemented using two technologies—NanGate45, which is open source, and GF12, which is a commercial GlobalFoundries FinFET process. (The TPU results reported in Nature used even more advanced process technologies.) Kahng’s team measured the same six metrics Mirhoseini and Goldie did in their Nature paper: area, routed wire length, power, two timing metrics, and the previously mentioned proxy cost. (Proxy cost is not an actual metric used in production, but it was included to mirror the Nature paper.) The results were mixed.
As it did in the original Nature paper, reinforcement learning beat RePlAce on most metrics for which there was a head-to-head comparison. (RePlAce did not produce an answer for the largest of the three designs.) Versus simulated annealing, CT won more than it lost on the production metrics.
For these experiments, the big winners were the newest entrants CMP and AutoDMP, which delivered the best metrics in more cases than any other method.
In the tests meant to match Stronger Baselines, using older benchmarks, both RePlAce and simulated annealing almost always beat reinforcement learning. But these results report only one production metric, wire length, so they don’t present a complete picture, argue Mirhoseini and Goldie.
A Lack of Learning
Understandably, Mirhoseini and Goldie have their own criticisms of MacroPlacement work, but perhaps the most important is that it did not use neural networks that had been pretrained on other chip designs, robbing their method of its main advantage. Circuit training “unlike any of the other methods presented, can learn from experience, producing better placements more quickly with every problem it sees,” they wrote in an email.
But in the MacroPlacement experiments each Circuit Training result came from a neural network that had never seen a design before. “This is analogous to resetting AlphaGo before each match… and then forcing it to learn how to play Go from scratch every time it faced a new opponent!”
The results from the Nature paper bear this out, showing that the more blocks of TPU circuitry the system learned from, the better it placed macros for a block of circuitry it had not yet seen. It also showed that a reinforcement learning system that had been pretrained could produce a placement in six hours of the same quality as an untrained one after 40 hours.
Reinforcement Learning vs. Everybody
Circuit training (Google’s open source reinforcement learning placement tool) was pitted against placement algorithms (RePlAce, Simulated annealing, and AutoDMP) as well as a commercial software (CMP) and a human expert. The tests were on three designs implemented in two process technologies (NG45 and GF12). All values are normalized to Circuit Training’s result. Smaller numbers are better. Note that RePlAce did not deliver a result for the largest design, MemPool.
New Controversy?
Kahng’s ISPD presentation emphasized a particular discrepancy between the methods described in Nature and those of the open-source version, Circuit Training. Recall that, as a preprocessing step, the reinforcement learning method gathers up the standard cells into clusters. In Circuit Training that step is enabled by commercial EDA software that outputs the netlist—what cells and macros are connected to each other—and an initial placement of the components.
According to Kahng, the existence of an initial placement in the Nature work was unknown to him even as a reviewer of the paper. According to Goldie, generating the initial placement, called physical synthesis, is standard industry practice because it guides the creation of the netlist, the input for macro placers. All placement methods in both Nature and MacroPlacement were given the same input netlists.
Does the initial placement somehow give reinforcement learning an advantage? Yes, according to Kahng. But it’s not clear from the experiments so far to what extent or even why. His group did experiments that fed three different impossible initial placements into Circuit Training and compared them to a real placement. Routed wirelengths for the impossible versions were between 7 and 10 percent worse.
Mirhoseini and Goldie counter that the initial placement information is only used for clustering standard cells, which reinforcement learning does not place. The macro-placing reinforcement learning portion has no knowledge of the initial placement, they say. What’s more, providing impossible initial placements may be like taking a sledgehammer to the standard cell clustering step and therefore giving the reinforcement learning system a false reward signal. “Kahng has introduced a disadvantage, not removed an advantage,” they write.
Kahng suggests that more carefully designed experiments are forthcoming.
Moving On
This dispute has certainly had consequences, most of them negative. Chatterjee is locked in a wrongful termination lawsuit with Google. Kahng and his team have spent a great deal of time and effort reconstructing work done—perhaps several times—years ago. After spending years fending off criticism from unpublished and unrefereed research, Goldie and Mirhoseini, who’s aim was to help improve chip design, have left a field of engineering that has historically struggled to attract female talent. Since August 2022 they’ve been at Antrhopic working on reinforcement learning for large language models.
If there’s a bright side, it’s that Kahng’s effort offers a model for open and reproducible research and added to the store of openly available tools to push this part of chip design forward. That said, Mirhoseini and Goldie’s group at Google had already made an open-source version of their research, which is not common for industry research and required some non-trivial engineering work.
Despite all the drama, the use of machine learning generally, and reinforcement learning specifically, in chip design, has only spread. More than one group was able to build on Morpheus even before it was made open source. And machine learning is assisting in ever growing aspects of commercial EDA tools, such as those from Synopsys and Cadence.
But all that good could have happened without the unpleasantness.
To Probe Further:
The MacroPlacement project is extensively documented on GitHub.
Andrew Kahng documents his involvement with the Nature paper here. Nature published the peer review file in 2022.
IEEE Spectrum




