How We Built Rufus, Amazon’s AI-Powered Shopping Assistant
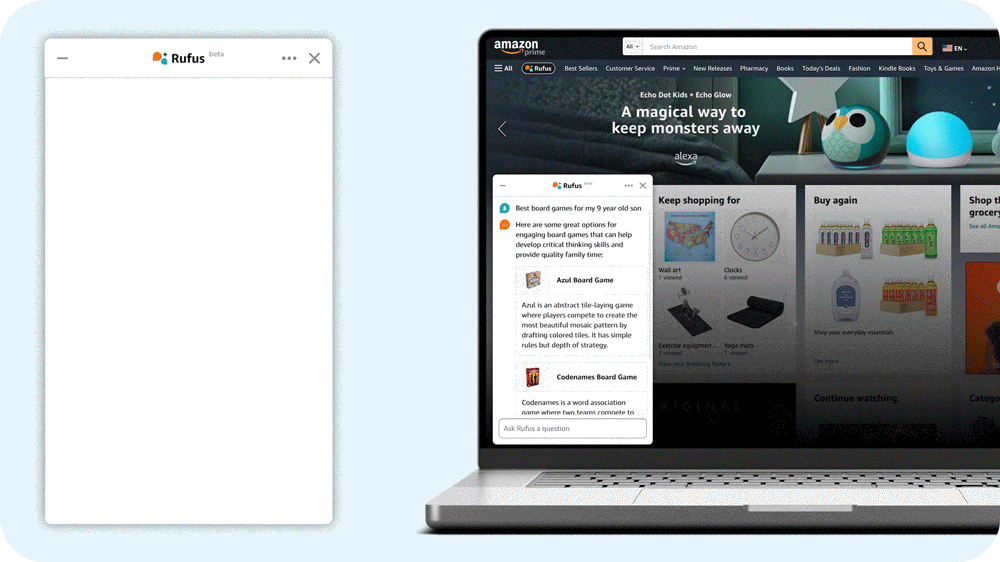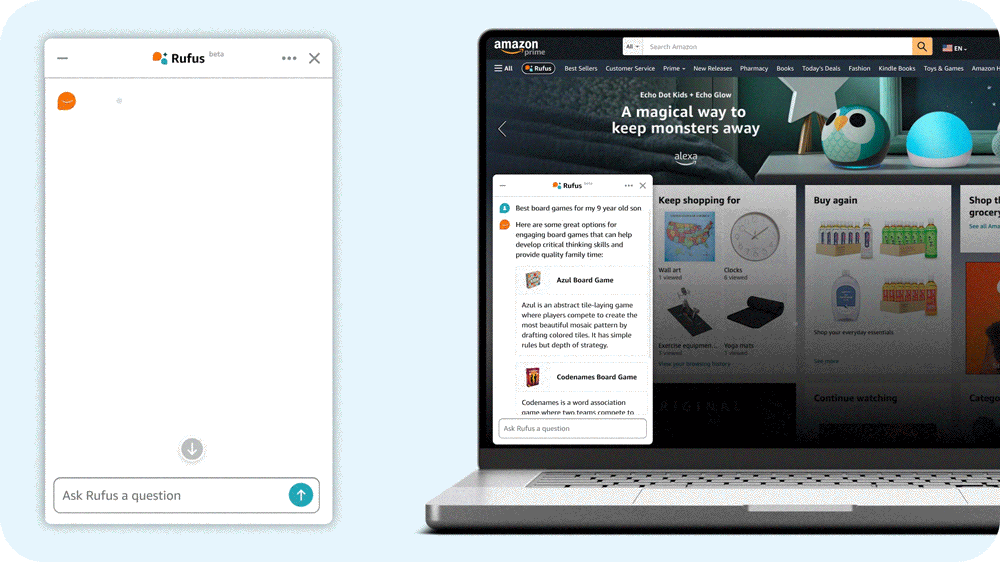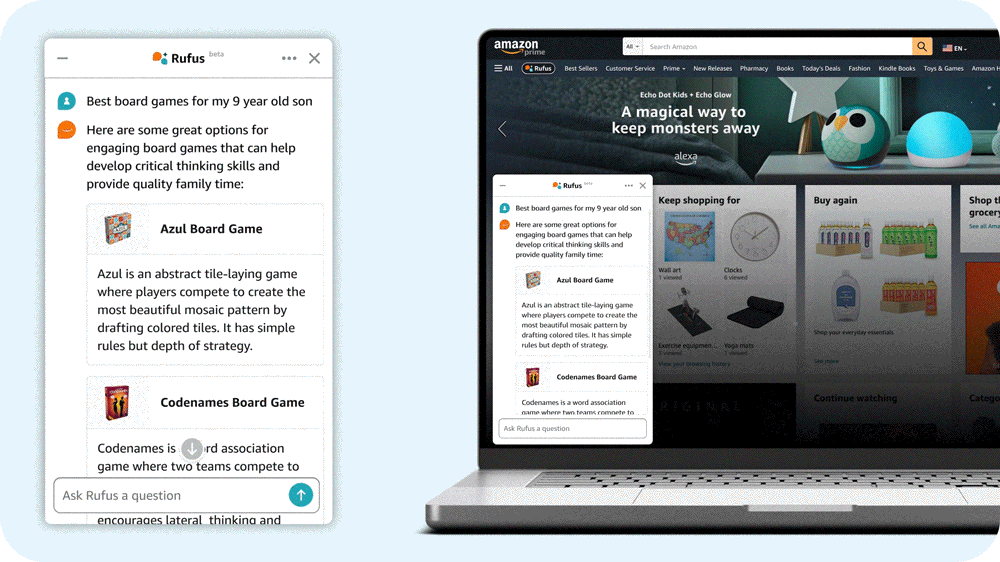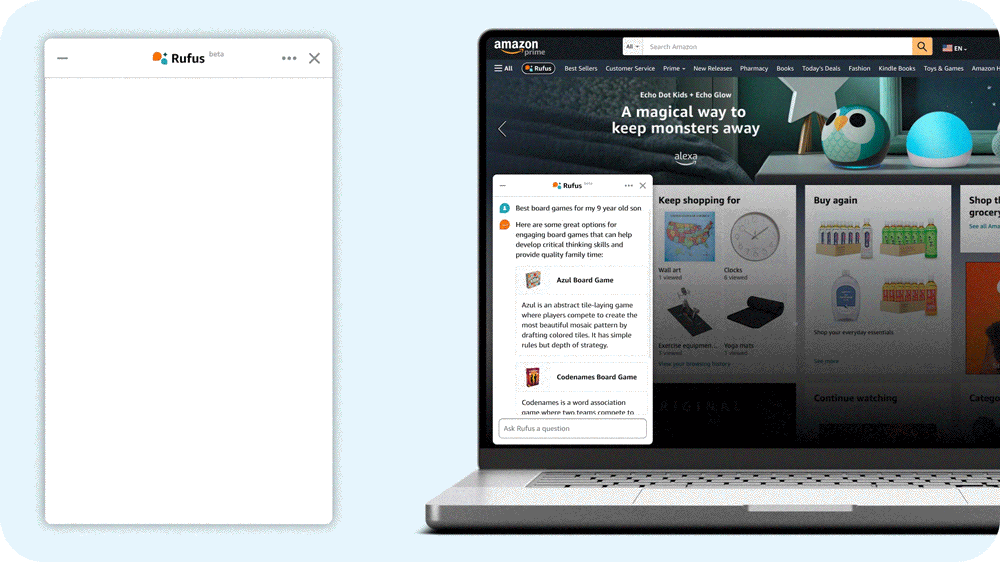
“What do I need for cold weather golf?”
“What are the differences between trail shoes and running shoes?”
“What are the best dinosaur toys for a five year old?”
These are some of the open-ended questions customers might ask a helpful sales associate in a brick-and-mortar store. But how can customers get answers to similar questions while shopping online?
Amazon’s answer is Rufus, a shopping assistant powered by generative AI. Rufus helps Amazon customers make more informed shopping decisions by answering a wide range of questions within the Amazon app. Users can get product details, compare options, and receive product recommendations.
I lead the team of scientists and engineers that built the large language model (LLM) that powers Rufus. To build a helpful conversational shopping assistant, we used innovative techniques across multiple aspects of generative AI. We built a custom LLM specialized for shopping; employed retrieval-augmented generation with a variety of novel evidence sources; leveraged reinforcement learning to improve responses; made advances in high-performance computing to improve inference efficiency and reduce latency; and implemented a new streaming architecture to get shoppers their answers faster.
How Rufus Gets Answers
Most LLMs are first trained on a broad dataset that informs the model’s overall knowledge and capabilities, and then are customized for a particular domain. That wouldn’t work for Rufus, since our aim was to train it on shopping data from the very beginning—the entire Amazon catalog, for starters, as well as customer reviews and information from community Q&A posts. So our scientists built a custom LLM that was trained on these data sources along with public information on the web.
But to be prepared to answer the vast span of questions that could possibly be asked, Rufus must be empowered to go beyond its initial training data and bring in fresh information. For example, to answer the question, “Is this pan dishwasher-safe?” the LLM first parses the question, then it figures out which retrieval sources will help it generate the answer.
Our LLM uses retrieval-augmented generation (RAG) to pull in information from sources known to be reliable, such as the product catalog, customer reviews, and community Q&A posts; it can also call relevant Amazon Stores APIs. Our RAG system is enormously complex, both because of the variety of data sources used and the differing relevance of each one, depending on the question.
Every LLM, and every use of generative AI, is a work in progress. For Rufus to get better over time, it needs to learn which responses are helpful and which can be improved. Customers are the best source of that information. Amazon encourages customers to give Rufus feedback, letting the model know if they liked or disliked the answer, and those responses are used in a reinforcement learning process. Over time, Rufus learns from customer feedback and improves its responses.
Special Chips and Handling Techniques for Rufus
Rufus needs to be able to engage with millions of customers simultaneously without any noticeable delay. This is particularly challenging since generative AI applications are very compute-intensive, especially at Amazon’s scale.
To minimize delay in generating responses while also maximizing the number of responses that our system could handle, we turned to Amazon’s specialized AI chips, Trainium and Inferentia, which are integrated with core Amazon Web Services (AWS). We collaborated with AWS on optimizations that improve model inference efficiency, which were then made available to all AWS customers.
But standard methods of processing user requests in batches will cause latency and throughput problems because it’s difficult to predict how many tokens (in this case, units of text) an LLM will generate as it composes each response. Our scientists worked with AWS to enable Rufus to use continuous batching, a novel LLM technique that enables the model to start serving new requests as soon as the first request in the batch finishes, rather than waiting for all requests in a batch to finish. This technique improves the computational efficiency of AI chips and allows shoppers to get their answers quickly.
We want Rufus to provide the most relevant and helpful answer to any given question. Sometimes that means a long-form text answer, but sometimes it’s short-form text, or a clickable link to navigate the store. And we had to make sure the presented information follows a logical flow. If we don’t group and format things correctly, we could end up with a confusing response that’s not very helpful to the customer.
That’s why Rufus uses an advanced streaming architecture for delivering responses. Customers don’t need to wait for a long answer to be fully generated—instead, they get the first part of the answer while the rest is being generated. Rufus populates the streaming response with the right data (a process called hydration) by making queries to internal systems. In addition to generating the content for the response, it also generates formatting instructions that specify how various answer elements should be displayed.
Even though Amazon has been using AI for more than 25 years to improve the customer experience, generative AI represents something new and transformative. We’re proud of Rufus, and the new capabilities it provides to our customers.
IEEE Spectrum




